When Agent Memory Becomes an Echo Chamber
I built a small LLM-based consumer simulation with three very different synthetic people: Maya, Raj, and Elena.
I expected them to browse different products and make decisions based on their personalities and budgets. Instead, all three converged on the same behavior: buying the same drip coffee for 80+ consecutive days.
At first, this looked like a simulation bug. It wasn’t. The memory system had created an echo chamber.
The LLM was summarizing past behavior into long-term memory. Future LLM calls were then reading those summaries as consumer identity. Buying coffee started as a small repeated choice that became “who they were,” because memory kept feeding the pattern back into the next decision.
The Setup: 3 Personas, 1 Narrow World
I started small: three synthetic consumers, a retail world of 55 items across groceries, electronics, and dining, two stores: a budget retailer and a mainstream retailer, and a daily simulation loop.
- Maya is a 28-year-old price-sensitive grad student in Boston. She lives on a $2,400 monthly stipend and has $48,000 in student loans.
- Raj is a 41-year-old software engineering manager in suburban Texas. He earns $11,500/month, has a $285,000 mortgage, is brand-loyal, and has a family of four.
- Elena is a 67-year-old retired schoolteacher in Albuquerque. She lives on a fixed $3,100 pension and her savings.
I call Maya, Raj, and Elena “consumers” rather than “agents” because they are not independent processes. They are persona records plus event history. A shared stateless BehaviorEngine makes the daily decisions for all of them through LLM calls.
Each consumer is defined as a YAML file with identity, economics, Big Five personality scores, value vectors like price sensitivity and brand affinity, and life stage details.
Each simulated day, a shared BehaviorEngine used Claude Sonnet 4.6 to choose structured actions for each consumer: view, cart_add, purchase, or abandon. The model returned JSON through tool use, so the outputs could be parsed and analyzed.
To give each consumer long-term memory, I added a Reflection engine. Every seven simulated days, a separate LLM call reviewed that consumer’s recent transactions and wrote 2–3 observations about their behavior. Those reflections were then included in the daily decision prompt for the next week.
The idea was to write a weekly reflection, feed it back into the next week’s daily decisions along with recent history, and keep each consumer consistent over time.
The Baseline Run
I ran a 90-day baseline with all three consumers. The results looked wrong almost immediately.
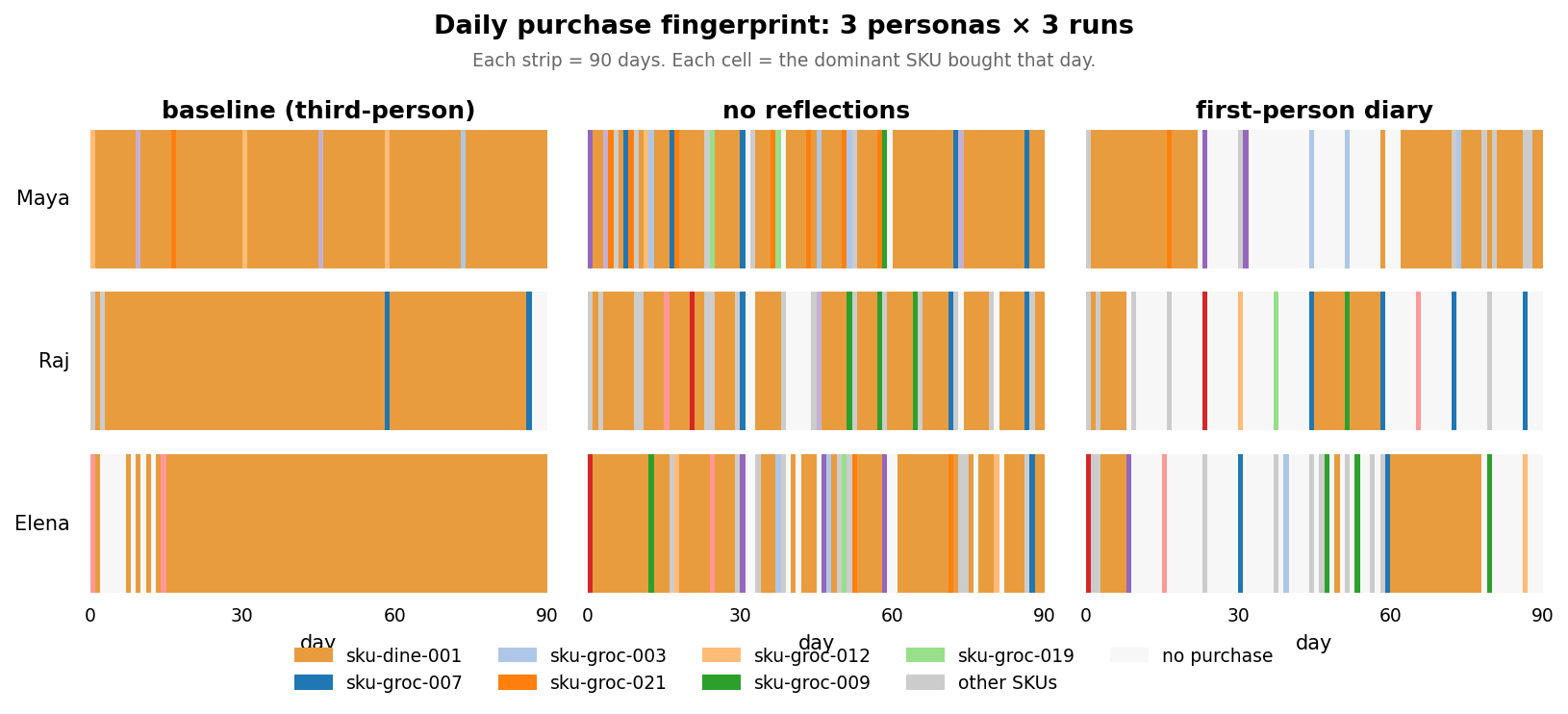
1. Everyone bought the same coffee, almost every day
Despite different incomes, ages, personalities, and budgets, all three consumers converged on the same item: Coffee Shop Drip Coffee.
Maya bought it on 88 of 90 days. Raj bought it for 84 consecutive days. Elena spent 83% of her cart additions on this one item.
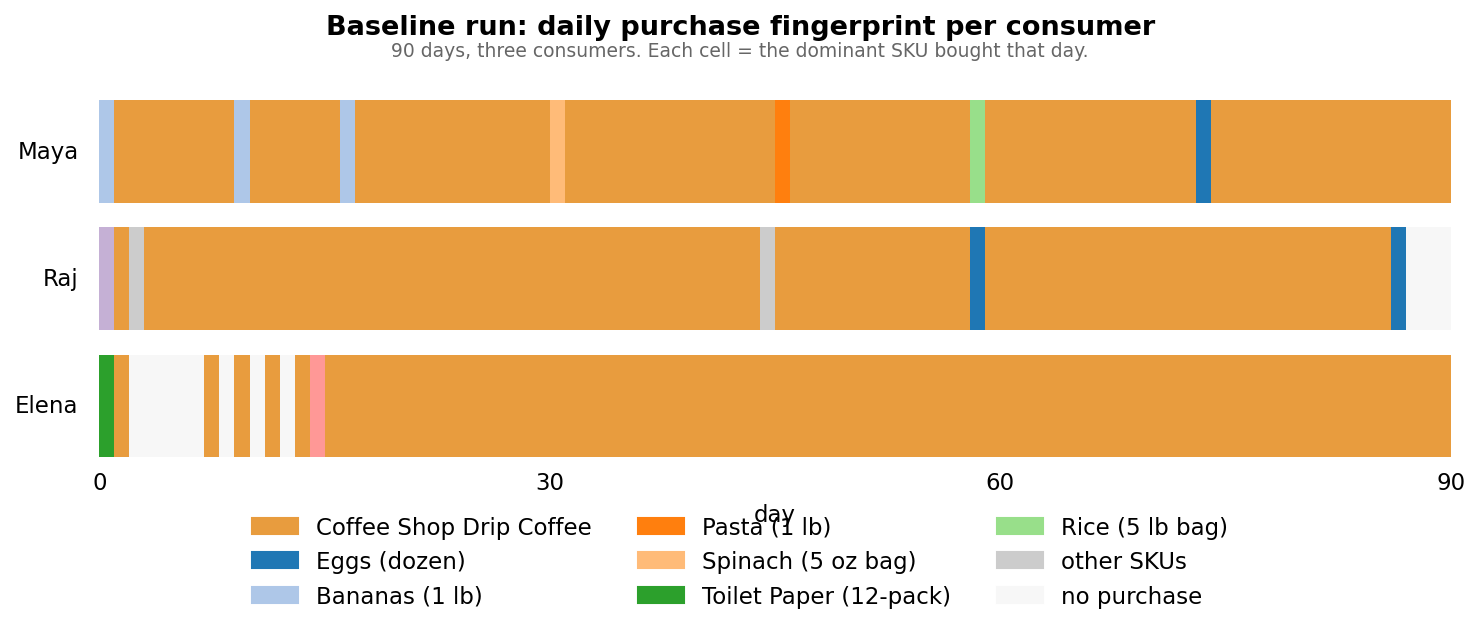
2. Exploration stopped within the first two weeks
I counted how many unique items each consumer had added to cart at least once. Raj and Elena reached their final set of explored items within the first two days. Maya explored slightly more, but eventually flattened out too.
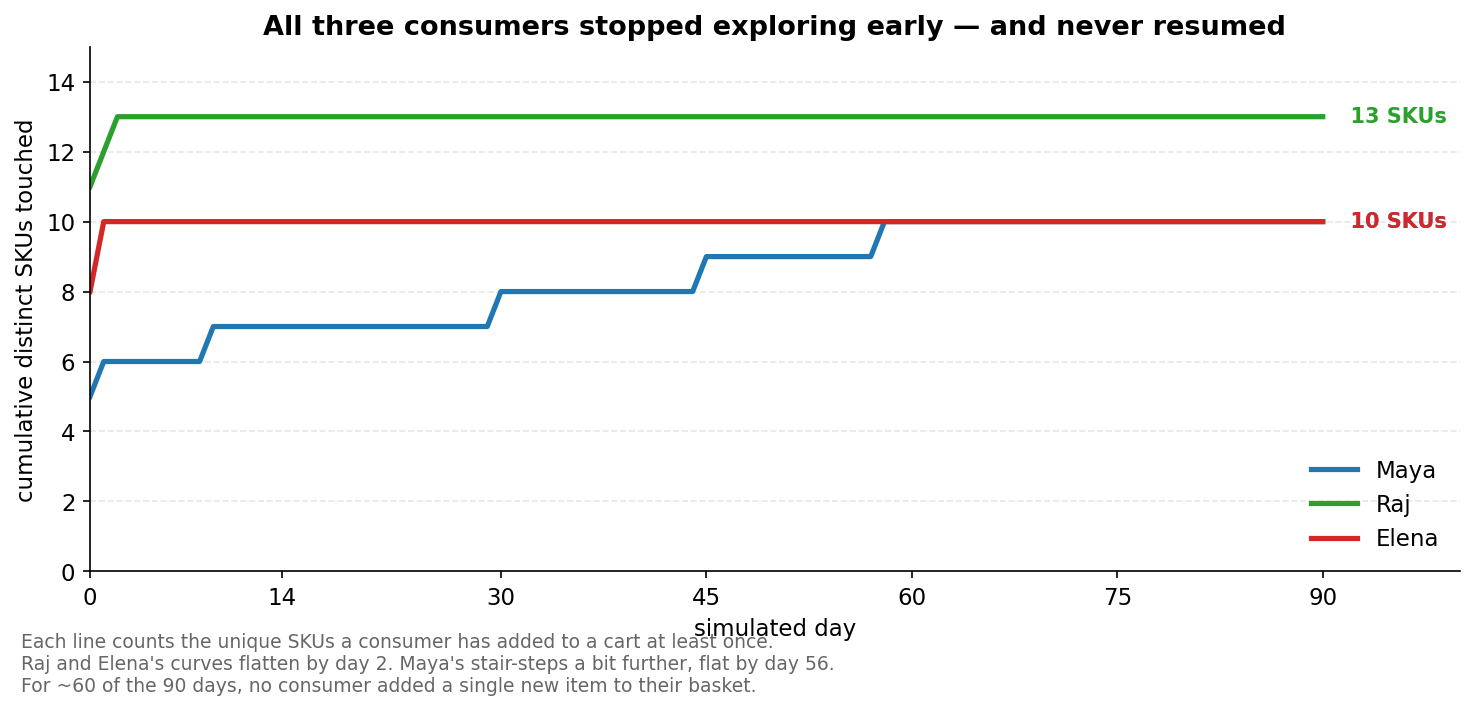
Across 263 total purchases, not one consumer bought an electronics item. No one bought premium phones. No one tried premium dining. No one meaningfully explored higher-end options.
That was especially strange for Raj. His persona had high income, strong brand affinity, and low price sensitivity. But he still behaved like a constrained bargain shopper.
Despite spending almost nothing, all three consumers actually grew their cash on hand over the 90 days — because the coffee habit was so cheap relative to their incomes.
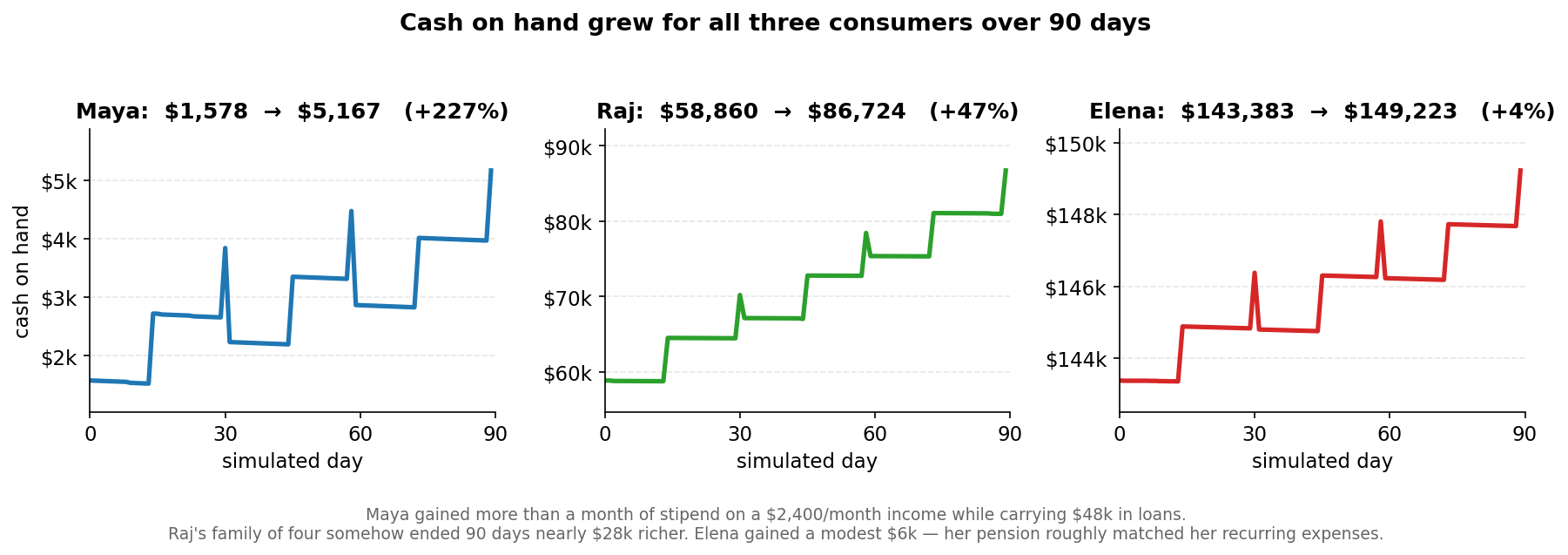
3. One moment of in-character behavior
On day 45, February 14th, Maya considered a Valentine’s Day brunch or dinner for two, then abandoned it because $48 felt too expensive given her student loans and tight budget.
The reflection captured it:
“Valentine’s Day temptation — briefly considered brunch or a dinner for two, but $48 is too steep given debt load and tight monthly budget; Maya decides the occasion doesn’t justify the spend.”
This was the behavior I expected to see more often: contextual and in-character. It happened once across 270 simulated person-days.
What Was Actually Happening
I looked at the weekly reflections. The model spotted the pattern correctly. Maya had a high openness score. She was supposed to explore. But the model’s own memory summaries kept describing her as someone locked into a repeated coffee habit.
Here is Maya’s week-4 reflection:
“The sku-dine-001 daily purchase streak has now extended unbroken across all 7 days of this window (Days 28–35), surviving a $1,605 recurring expense shock on Day 31 without any interruption, which signals that this $2.98 item has crossed from discretionary habit into a psychologically protected essential — the one spending behavior insulated from even acute cash-flow pressure.”
A few weeks later, the reflection became even more explicit:
”[…] the behavioral system has reached a self-reinforcing equilibrium where even Maya’s high openness-to-experience trait is producing no observable consumer-side variance — a structural decoupling of personality disposition from actual purchasing behavior.”
Each daily decision was a fresh LLM call. The model making the decision did not directly remember previous days. It only saw the persona, recent events, and reflection summaries.
The reflection described Maya as having a protected coffee habit. The next daily decision call treated that as a behavioral fact. Maya bought the coffee again. The next weekly reflection described the habit as even more entrenched. That stronger reflection went back into the next prompt.
The summary stopped being a record of what happened. It became a reason to do it again.
You can see this directly in the language the reflections used over time. Words like “habit,” “infrastructure,” “automaticity,” “entrenched,” and “streak” appeared more and more frequently in the baseline reflections — and far less in the first-person diary condition.
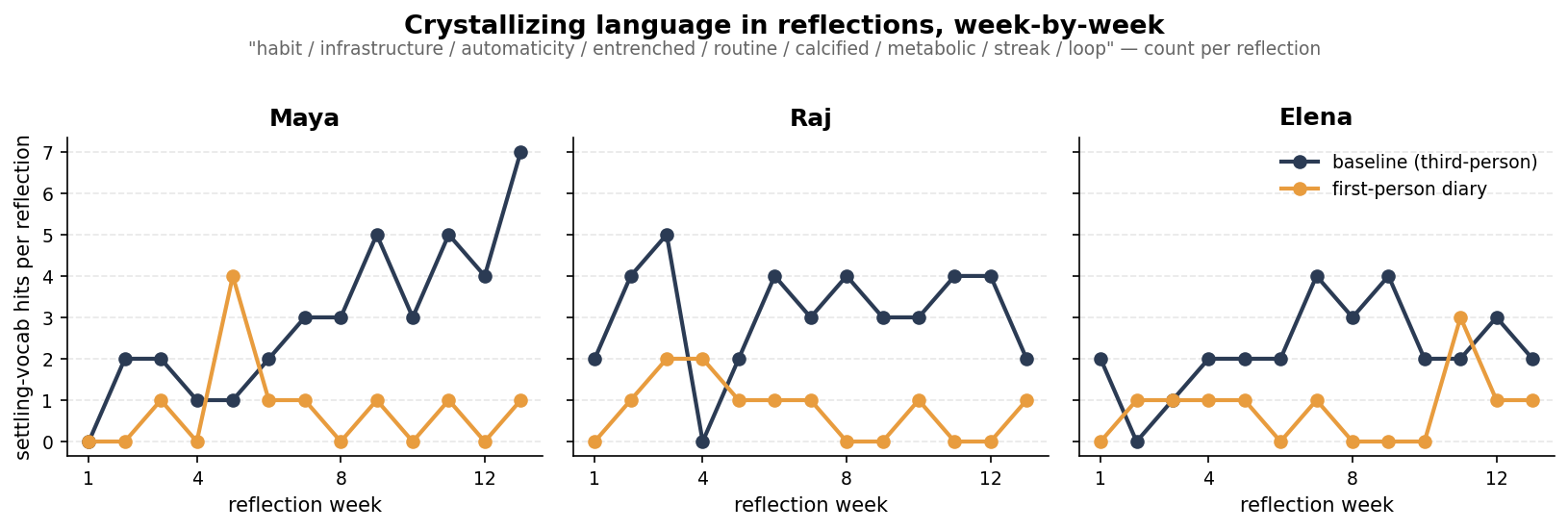
Breaking the Loop
If the reflection loop was causing the convergence, then breaking that loop should reduce it. I ran two additional 90-day variations.
-
No-reflection control. The reflection step and weekly LLM call disabled entirely. Consumers still had persona data and recent events, but no long-term reflective memory.
-
First-person diary condition. Instead of writing third-person behavioral analysis, the reflection engine wrote short diary-style entries in the consumer’s own voice.
The baseline prompt looked like this:
“You are summarizing a synthetic consumer’s recent week. Write 2–3 abstract observations about their state, behavior patterns, or trajectory. Be specific, not generic. Each observation: one sentence.”
The first-person version looked like this:
“You are writing a private diary entry as this consumer. Write 2–3 short first-person reflections in their voice — things they noticed about their week, things they’re considering, things they might do differently. Use ‘I’, not ‘they’. Sound like a personal journal entry, not a behavioral analysis. It’s fine to be uncertain, ambivalent, or contradictory — diary entries usually are.”
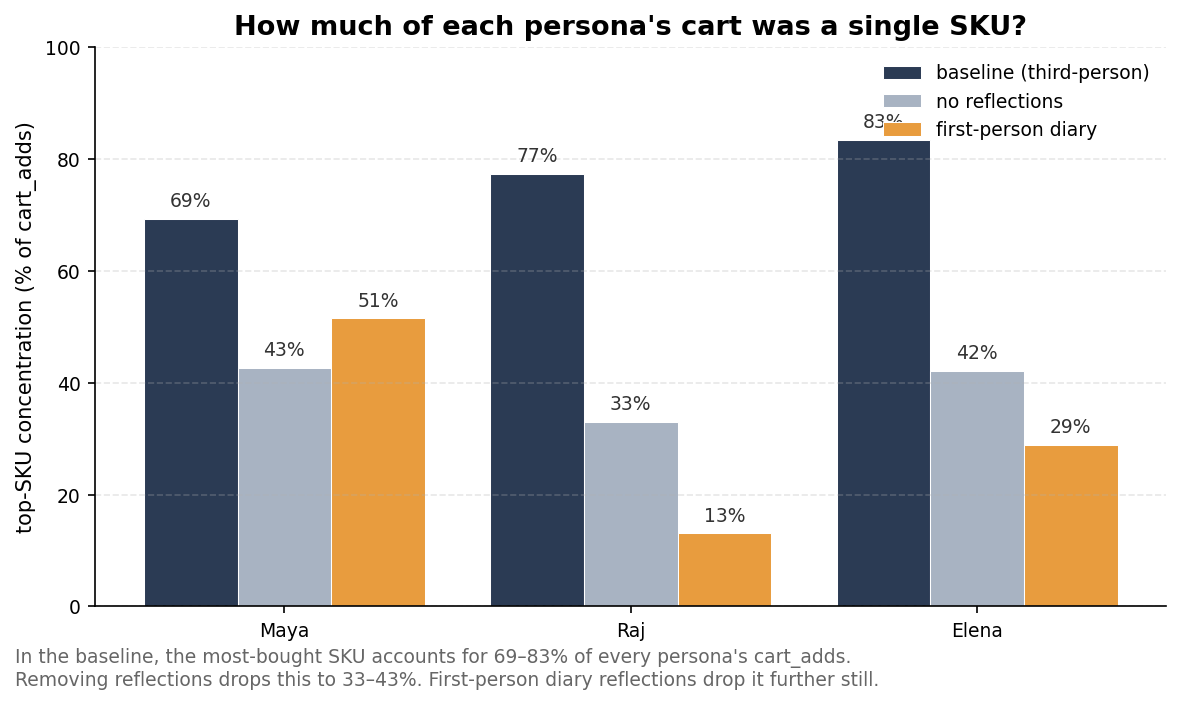
In this small run, both interventions reduced the coffee loop. The first-person diary broke it more thoroughly.
Coffee habit broke
The no-reflection condition produced more variety than the baseline, but still showed repetitive behavior.
The first-person diary condition made the shoppers diverge: more no-purchase days, more varied item choices, and less lock-in around a single product. It also made the consumers more distinguishable — between-persona similarity dropped from 0.99 to 0.69. Maya shifted toward weekend dining. Raj shifted toward household groceries. Elena spread purchases across groceries, dining, and one electronics item.
Cart abandonments increased 25× compared to baseline
Cart abandonments were moments when a consumer paused on a purchase and walked away. In the first-person diary condition, abandonments increased 25× and appeared throughout the run, rather than only as a single Valentine’s Day exception.
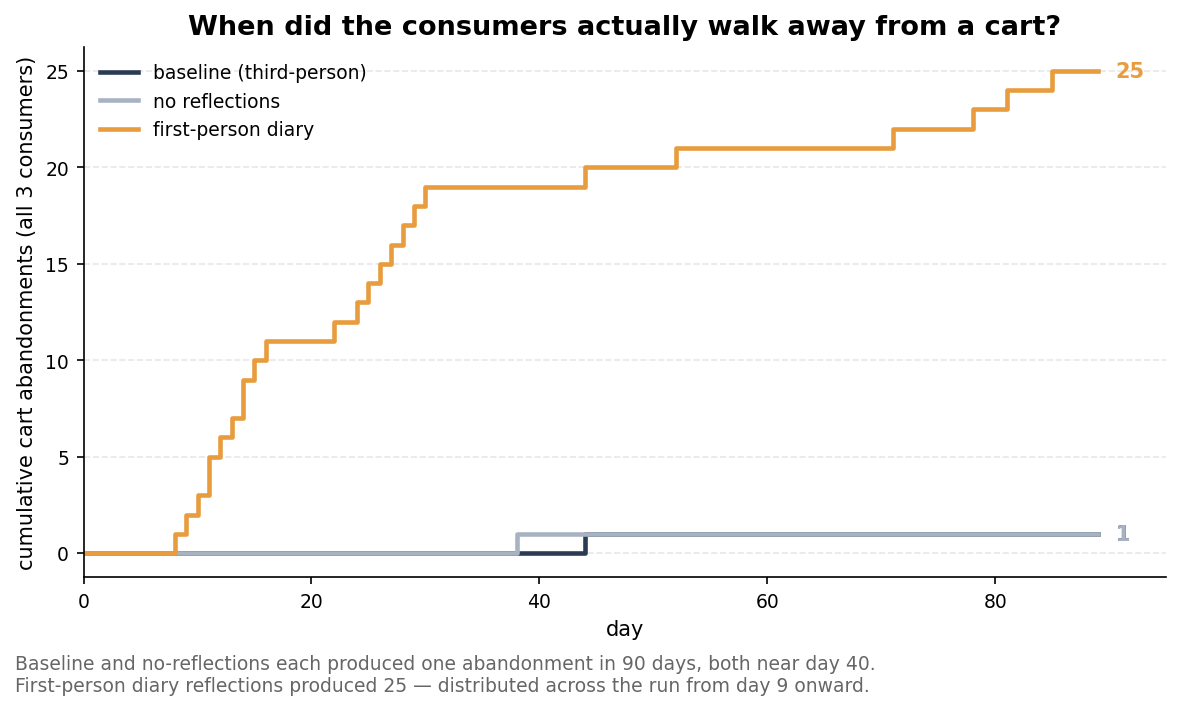
The consumers considered alternatives, walked away from carts, and produced reasoning that sounded more like internal thoughts than external behavioral analysis.
The Takeaway
The main lesson for me is that agent memory actively shapes future decisions.
When one LLM summarizes behavior and another LLM later reads that summary, the summary can become a behavioral prior. If the memory says, “this is who the consumer is,” the next decision may make that even more true.
For agent systems that rely on reflection, the format of memory may matter as much as the content inside it.
It also made me wonder what gets lost when agents compress history. Do they preserve only the fact — “Maya buys coffee every day” — or also the uncertainty around it: “Maya keeps buying coffee and is not sure whether it is comfort, habit, or bad spending”?
Both are summaries of the same behavior. But they create different decisions.
Caveats
This was a small experiment: three personas, one run per condition, one model, a small catalog, and a simplified environment with no real-world validation. The first-person prompt also changed multiple variables at once: perspective, tone, uncertainty, and wording. So I cannot claim that first-person perspective alone caused the improvement.
What I Want to Try Next
Next, I want to test consumer behavior across more models, larger populations, longer runs, richer catalogs, and memory architectures such as episodic memory, uncertainty-aware summaries, and memory decay.
I’m also interested in evaluation metrics for detecting when agents become too repetitive, too similar, or disconnected from their personas.
The repo is at github.com/dkonidela/consumer-agents. If you build something, I’d love to hear about it.